
I had a conversation last month with a CEO who was confident his company was doing well in AI search.
"I asked ChatGPT what the best company in our space was," he said, "and it named us. So we're good."
I asked him how many times he'd checked. Once. I asked whether he'd tried Claude. He hadn't. I asked whether he'd tried slightly different phrasings. He looked at me like the question didn't make sense.
I get it. Most business owners aren't statisticians. The intuition is: I asked, it answered, the answer is what the answer is. But that intuition is wrong about how AI search actually works, and the consequence is a lot of false confidence and a lot of missed opportunities to improve.
AI output is variable. Significantly.
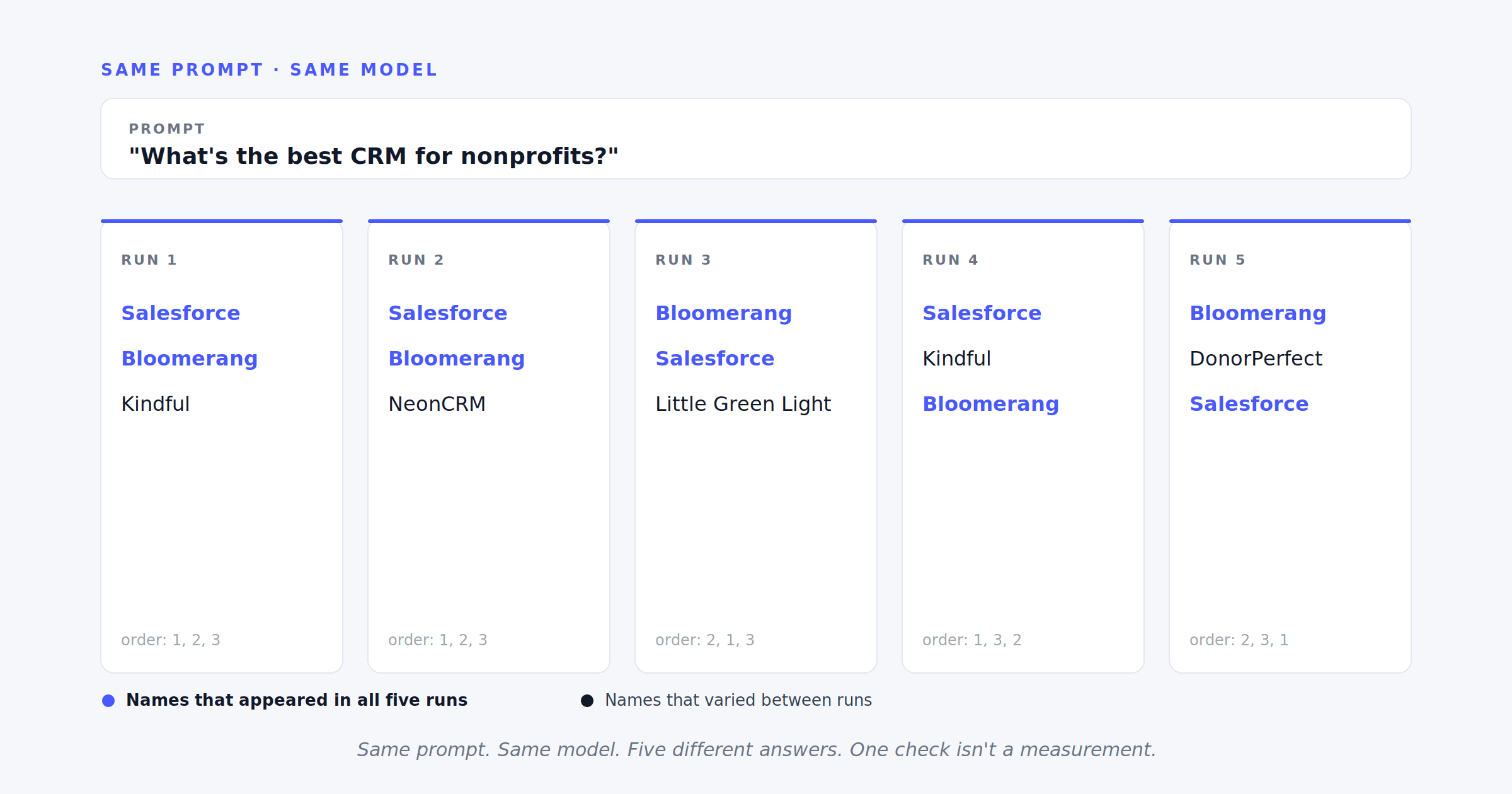
Here's the thing about large language models that anyone running a measurement program on them has to internalize: the same prompt, run twice, can produce different answers.
This isn't a bug. It's the fundamental nature of how these models work. Inference involves probability distributions and sampling, which means there's inherent randomness in the output. OpenAI, Anthropic, and Google all expose temperature settings that control this randomness, but even at the lowest setting, you get non-deterministic results on most real-world prompts.
For a question like "what's the best CRM for nonprofits," I've seen the same model return five different lists of three companies in ten consecutive runs. There was overlap — two or three names showed up consistently across runs — but the specifics changed each time. Order changed. New names appeared and disappeared.
If you ask once and get a good answer, you might just have gotten lucky on that run. If you ask once and get a bad answer, the same thing applies in reverse.
Variability across platforms is even larger
The differences within ChatGPT are real but not enormous. The differences between ChatGPT and Claude, or between Gemini and Perplexity, are large.
Each platform is a different model with different training data, different web-grounding strategies, and different fine-tuning. A business well-represented in ChatGPT's training data might be invisible on Claude. A business that ranks well on Perplexity — which heavily weights live web search — might not rank on a platform that relies more on training data.
If your customers use multiple AI platforms — and they do; research suggests typical AI users move between platforms depending on the task — checking one platform tells you about that platform, not about your AI visibility overall.
Wording matters more than you'd think
Try asking the same AI platform these three variations of essentially the same question:
- "What are the best email marketing platforms?"
- "Which email tool is easiest for non-technical users?"
- "Recommend an email marketing service for ecommerce."
You will get partially overlapping, partially different answers. Sometimes substantially different. Categories shift. The implicit weighting of "best" vs. "easiest" vs. "for ecommerce" pulls the model toward different parts of its training data.
This isn't a problem you can solve by picking the right wording. You can't, because there isn't one. Your customers ask the question dozens of different ways, and the right measurement strategy is one that samples across realistic variations — not one that picks a single phrasing and assumes it represents the universe.
What a real measurement looks like
If you're going to actually measure AI visibility — not just spot-check it — you need three things.
Multiple prompts per category. Not one. Five to ten prompts that represent the actual ways customers ask about your business. Different wording, different angles, different specificity.
Multiple samples per prompt per platform. Five samples per prompt per cycle is a defensible working baseline — enough to see whether your business shows up reliably or only occasionally, and to distinguish signal from single-run randomness. Fewer than that and you're back to anecdote.
Tracking over time. AI platforms update. Web grounding indexes change. New competitors emerge. New content gets crawled. A measurement that was accurate three months ago may not be accurate today. Monthly cadence is enough to spot directional movement; bi-weekly or weekly is what you want once you're actively optimizing.
Doing this by hand is impractical. A real program for one business involves running hundreds to thousands of AI prompts per month across five platforms, parsing the responses, and aggregating the results. That's not a spreadsheet problem. It's why measurement tools exist.
The same logic as any marketing test
If you've read anything I've written about marketing testing, this should feel familiar. The same principles apply.
A small test can't detect a small effect. Five samples can tell you whether you're mentioned 80% of the time or 20% of the time. They can't tell you whether you went from 35% to 38%. If you want to detect a few-point improvement, you need more samples — or more time and more prompts feeding the same trend line.
A single observation is anecdote, not data. The CEO who asked ChatGPT once and got a good answer didn't measure his AI visibility. He took one sample. He doesn't actually know whether he gets recommended 90% of the time or 10% of the time.
Baseline before you optimize. You can't tell whether a change improved your AI visibility unless you know what it was before. Run a real measurement, write down the result, then make the change.
The bigger point
AI visibility is measurable. It's just not measurable through casual prompting. Treat it the way you'd treat any other important marketing metric: set up a real measurement program, sample appropriately, track over time, and let the data tell you what's working.
The businesses that get this right will know exactly what their AI visibility is. The businesses that get it wrong will keep asking ChatGPT once, getting whatever they get, and assuming that single answer represents reality.
It doesn't.
LLMLens runs five samples per prompt per cycle across ChatGPT, Claude, Gemini, Perplexity, and Google AI — exactly because of the variability described above. See how the methodology works.